




By Sander van de Graaf and Daniel Jakobsson
Introduction
At Downdetector, we have moved all of our infrastructure to various serverless services on AWS. As of 2020, we no longer have any EC2 instances running. This saves us massive operational overhead and allows us to focus on building the best product for our users.
We always battle with larger and bigger outages on the internet every month. People around the world now flock to Downdetector whenever an outage happens. Of course, this means we have to make all our systems and services scale rapidly. Currently, our architecture allows us to scale to meet the demand we need, without any manual intervention.
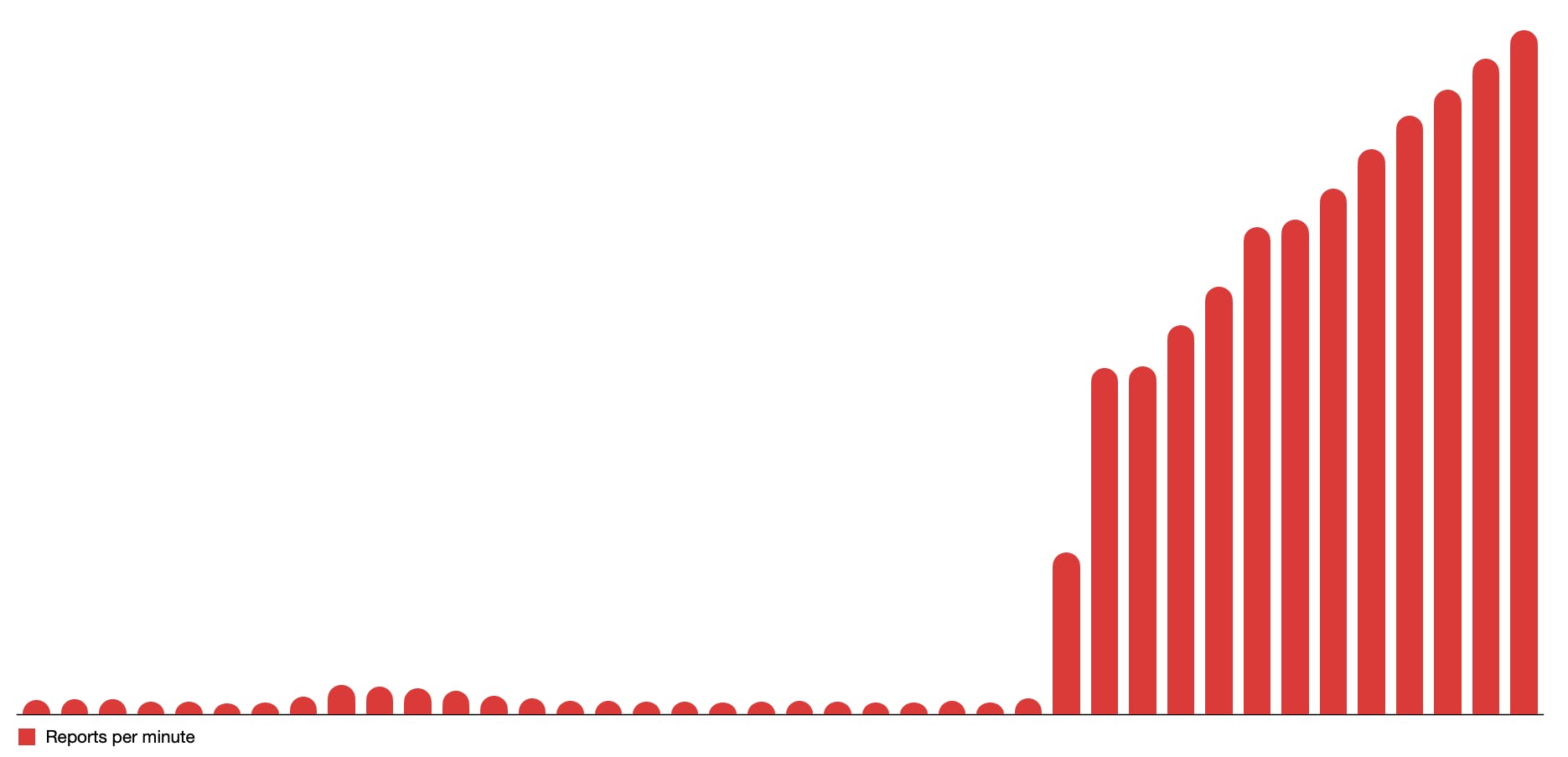 Figure 1: Whenever a large outage happens, the number of reports will scale up in a matter of minutes or seconds. In this example, 10x in 1 minute, 20x in 2 minutes, and more from there on.
Figure 1: Whenever a large outage happens, the number of reports will scale up in a matter of minutes or seconds. In this example, 10x in 1 minute, 20x in 2 minutes, and more from there on.
There is one aspect of our architecture that still needs improvement. We are running from inside a single region in AWS: eu-west-1. We want to change that, as we want Downdetector to be available whenever any AWS region goes down. Recent AWS regional outages have only made this issue more pressing. To mitigate this risk, we’re going to deploy to a full active-active multi-region setup.
While looking for material and best practices on these kinds of architectures, we’ve found that there is surprisingly little information to be found. We hope this series of posts will give some more clarity and insights into what you can expect going into such a project.
Here are some of the common reasons to go multi-region:
- Lowering latency to end-users
- For legal reasons (specific data needs to reside in a specific region)
- For Durability/High Availability reasons
Our primary reason for going multi-region is mostly based on High Availability (HA). We want the site to be available if eu-west-1 ever goes down. We want to be able to tell what is happening and keep our users informed. Our second reason is for our enterprise API clients to have lower latencies to our API data, and for our public users to be able to get to our site even faster (shorter routes), better SEO.
Of course, as with any large distributed system, it's going to be very hard to make sure that no service within AWS is depending on some other service in another region. For some services, it is known what their cross-regional dependencies are (looks at CloudFront and us-east-1), for other services it's not well known. We'll try to minimize this impact where we can and where it makes sense, while keeping a pragmatic approach.
Current setup
As mentioned before, our current architecture lives inside eu-west-1. Our application layer consists of a combination of Lambda, Kinesis, and other managed AWS services. All of these are easy to deploy to another region. Our data layer consists of OpenSearch (Elasticsearch), DynamoDB, and MySQL RDS.
Global data consistency is a difficult challenge; AWS-managed database services help to reduce the operational complexity of maintaining such systems. For more details about our current application architecture and data flow, we recommend watching our ServerlessConf talk about it: Detecting Outages at Scale
Desired setup
The plan is to have two regions available in a full active-active state. We want to keep our regions as isolated as possible, they should know nothing about the other regions involved (except the edge layers, but we’ll get to that later). We will deploy all of our services to both regions, which will be straightforward as our stack is completely defined in CloudFormation. Most of our microservices are based on the Serverless Framework, and each service has its deploy pipeline embedded into its respective repository. Since 2019, We have made sure that all of the code we write is region agnostic. Deploying those microservices will be as easy as changing the environment variable during the service bootstrap.
 Figure 2: Simplified architecture overview
Figure 2: Simplified architecture overview
Data layer
The more difficult part is our data layer. For reasons we won't go into now, we are running our primary data source on MySQL RDS. Fortunately, AWS has a service that makes multi-region easier: RDS Aurora. We will need to upgrade MySQL RDS to Aurora multi-region. For the secondary region, we will use write forwarding to receive writes which will then be pushed to the primary region. These writes will be synchronized back to the secondary regions on the internal AWS backend network. Our services in each region will think they are writing locally, which is excellent for keeping things simple.
Aurora multi-region can be optimized for different consistency configurations. The trade-offs overlap with the CAP theorem. Aurora Global has three different consistency modes, the trade-off being between Performance and Consistency. Our application is already optimized for eventual consistency, so we'll optimize for performance (the default).
DynamoDB
DynamoDB is a different issue for us. We evaluated DynamoDB global tables but chose not to use this feature.
To explain this reasoning, we need to provide a little bit of background on the way we use DynamoDB. We have a microservice that creates lookup tables. This microservice syncs data from our primary data source (RDS) to DynamoDB. The data inside DynamoDB will be eventually consistent. Our lambdas can fetch the data from DynamoDB, without having to run inside a VPC and connect to RDS to fetch data. This greatly improves performance for Lambda and reduces the cold startup times. In addition, with DynamoDB, we don't have to think about connection pooling, and it's better suited for rapid scaling as we see during external outage scenarios.
The “problem” with Dynamo Global tables is that they would introduce a global resource into our regional stacks, which implies that one region is responsible for managing data in our other regions. This would then infer that we need to make switches in our Cloudformation templates and decide which region would be responsible for those resources. That's not what we want. We want to keep things simple, stupid. Each region should know nothing about other regions (isolation). And each region should be responsible for its lookup tables. Our services already handle eventual consistency gracefully, so for our use case, this is not the best solution. YMMV of course.
So instead, we'll keep our current lookup service as-is, and deploy it in both regions. The lookup service fetches the data from the local (regional) RDS endpoint and updates the DynamoDB tables accordingly. This way, we're not dependent on one region filling those lookup tables, but the regions are responsible for their own data flows and tables.
OpenSearch (Elasticsearch)
We use OpenSearch for time series and geospatial data queries on outage reports. This data is stored in multiple time-based indices.
Similar to DynamoDB, the same philosophy applies to our OpenSearch cluster. We evaluated using the new OpenSearch multi-region sync, and we tested this feature with multiple POC's. The present problem with OpenSearch multi-region sync is that replication only goes one way. This would mean that we would need to set up separate indices for different regions and adjust our queries to cross both indices, and if any region goes down, we would be missing data. Additionally, if we were to add more regions in the future, the sync matrix would become harder and harder to maintain (as each region would need to sync with all the other regions).
 Figure 3: OpenSearch multi-region sync is unidirectional
Figure 3: OpenSearch multi-region sync is unidirectional
Instead, we have decided to spin up separate OpenSearch clusters in each region and keep them fully isolated. We already have a process to backfill missed reports from the primary data source (RDS). Given the RDS Aurora multi-region sync, the data inside OpenSearch would be eventually consistent across regions.
Edge layer
To route between the different regions, we will need to update our edge configuration. We are currently using Cloudflare for our edge network layer. Route53 + CloudFront would also be a viable option.
Cloudflare will be configured with multiple endpoints and health checks so we can load balance between the two regions. We can also configure optimized paths if needed (forcing a specific network to a specific endpoint).
Observability
Our current application metrics, performance dashboards, and alarms will need to be optimized to allow for filtering between different regions. That way, we can see if a particular region is having issues, and can have our health checks respond accordingly if needed.
In addition, we will also start to measure where requests are coming from. Cloudflare sends the original request edge location (cf-colo) with each request. CloudFront has a similar header (x-amz-cf-pop). Storing these values will give us more insights in the flow of requests and origins in the past and future.
Deployments
Our current deployment model is built so that every service has their own deploy pipeline embedded in its CloudFormation stack. This will still be applicable. Whenever an engineer pushes code to specific branches (main/develop/etc.), these pipelines will get triggered.
We will extend this model by allowing deployments to specific regions, so that we can run A/B tests and give us more flexibility. For this we will create branches for specific regions. The service's deploy pipeline will trigger on both the global branch and the regional branch.
Of course, we will need to implement all these changes while operating a product at large scale. It's like adding a second engine to a car, while it's off-roading doing 90mph. Pretty nuts, but that's what is going to make it fun! :D
Tl;dr
We're planning to do some interesting things for our multi-region deployments. We'll share our learnings and pitfalls along the way, hopefully getting some valuable feedback and help other teams out which are facing the same step.
Also, if you like to work on these things: We're hiring!
We'd like to thank Brennen Smith, Luke Deryckx and everyone else who worked on this post.