



Using the CDK for Terraform to Generate Infrastructure as Code for Web Applications Across Multiple Accounts, Regions, and Stages: Part 1
Scaling Ookla's Terraform usage for future growth


by Garet Wirth
Cmd+C, Cmd+V
About a year ago, Ookla's Senior Platform Architect linked me to the Github repository for Terraform's Cloud Development Kit, or CDK, with a "this looks interesting" note. I perused the README and shrugged - I didn't quite understand why we would want to write code to generate code (to run our code). I felt like our Terraform implementation, based on the TerraServices model coined by Nicki Watt and presented here, was working fine for our AWS EC2-based workloads.
If you're unfamiliar or rusty with Terraform and its core concepts, I would encourage a quick brush up with Hashicorp's documentation before reading further.
Also around that time, we were hard at work migrating our web APIs to AWS's Elastic Container Service (ECS), many into multiple AWS regions. As we worked through several of these migrations, we noticed a pattern; we were doing quite a lot of copy-and-paste of our Terraform code. Even with heavy utilization of Terraform modules, each stage and regional replica required the same carbon-copy sections of HCL, Hashicorp's JSON-derived configuration language. When it was time to make a change to an application's infrastructure, we had to duplicate our work across all regions and stages. One of the most frequent comments on a certain SRE's pull requests was "don't forget to make these changes in aws-region-2, too." One would think after the umpteenth time I -- I mean, they -- would start to remember, but alas...
The Old Way
We can visualize our legacy TerraServices-based Terraform setup with a file tree:
├── envs
│ ├── aws-region-1
│ | └── speedtest-api
│ | ├── main.tf <-- defines prod & pre-prod stages
│ | ├── vars.tf
│ ├── aws-region-2
│ | └── speedtest-api
│ | ├── main.tf <-- defines prod regional replica
│ | ├── vars.tf
└── modules
└── project
├── ecs-app <-- referenced by both envs
├── ecs-app-dns <-- referenced multiple times by both envs
├── iam-app <-- referenced multiple times by both envs
... <many more>
and some (summarized) HCL from the "main.tf" files at /envs/aws-region-2/speedtest-api and /envs/aws-region-1/speedtest-api:
locals {
// Config for the various stages for this app.
ecs_config = {
prod = {
...
}
beta = {
...
}
staging = {
...
}
dev = {
...
}
experimental = {
...
}
}
}
// Security group for the app.
resource "aws_security_group" "security_group" {
...
}
// All needed ALB Target Groups.
module "target_group" {
for_each = local.ecs_config
source = "../../../modules/project/web-loadbalancer-additional"
...
}
// ECS services for all of the app stages.
module "ecs_app" {
for_each = local.ecs_config
source = "../../../modules/project/ecs-app"
...
}
// Production DNS
module "ecs_app_prod_dns" {
source = "../../../modules/project/ecs-app-dns"
...
}
// Pre-prod DNS entries
module "ecs_app_preprod_dns" {
for_each = { for k, v in local.ecs_config : k => v if k != "prod" }
source = "../../../modules/project/ecs-app-dns"
...
}
// IAM Role for production application
module "prod_task_role" {
source = "../../../modules/project/iam-app"
...
}
// IAM Role for pre-production replicas
module "dev_task_role" {
source = "../../../modules/project/iam-app"
...
}
// Logging resources
module "logging" {
source = "../../../modules/project/logging"
...
}
Though I omitted many of the details from the above code sample, the issue is clear -- each stage/regional replica of the application requires a lot of same-y boilerplate HCL. We tried to reduce this with for_each statements on our modules and liberal usage of dynamic blocks, but it only helped to a point.
New Ideas?
We toyed with the idea to scrap our existing modules and create a monolithic One Module To Rule Them All that merged the logic of our smaller modules. However, we felt we'd done a good job keeping the scope of our existing modules within the desired realm of "small but useful." Plus, we used them heavily outside of the ECS migration project. Redefining all of our infrastructure logic in a second location felt like an anti-pattern.
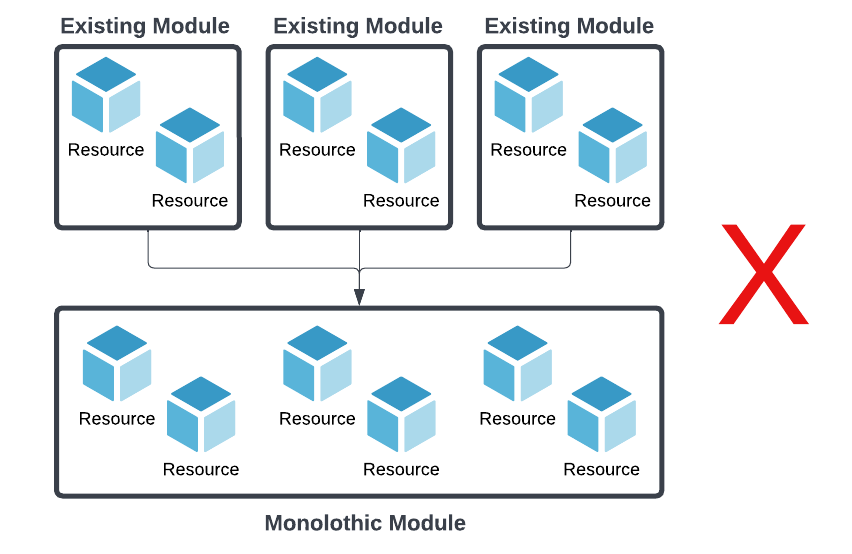
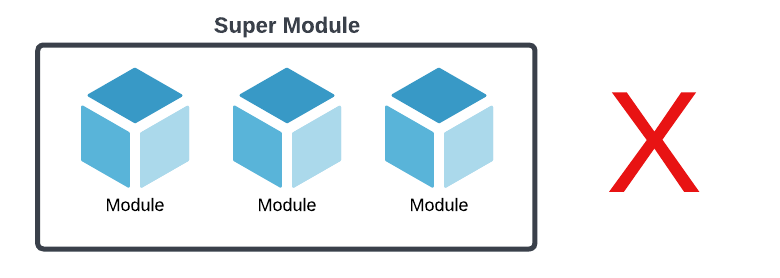
We had another idea to create a "super" Terraform module that referenced all of the other modules as submodules. However, given the number of variables and conditionals needed to define our various ECS workloads (loadbalanced vs. not loadbalanced, autoscaled vs. static, variable number of pre-production stages), we felt like it wasn't a useful level of abstraction and only added complexity.
While investigating both of the above ideas, another problem was becoming increasingly obvious -- HCL itself could be very limiting and very frustrating to work with. Once you try to get fancy with regional providers, loops, and conditionals within a module, HCL tends to explode. This isn't surprising as HCL is not a programming language; it's a declarative syntax with some helper functions baked in. Using it to code is like trying to train your cat to "shake" -- you aren't going to have a very good time.
If only there was a way to re-use our existing, battle-hardened Terraform modules via some sort of abstraction layer that eliminated HCL's inherent limitations and the need to manually copy/paste HCL...
The Magic of the CDK
After much discussion and many shrugging-person emojis, that same Senior Platform Architect brought back up the Terraform CDK as a possible solution. Suddenly what seemed like needless abstraction made perfect sense; Terraform and HCL allow an SRE team to declare their cloud infrastructure, but it does not do a good job of capturing how that team likes to (or needs to) declare it. This is what the CDK accomplishes -- it allowed us to codify our implementation strategies at scale.
Excited at the prospect of writing TypeScript instead of more HCL, we developed an architecture around our CDK implementation:
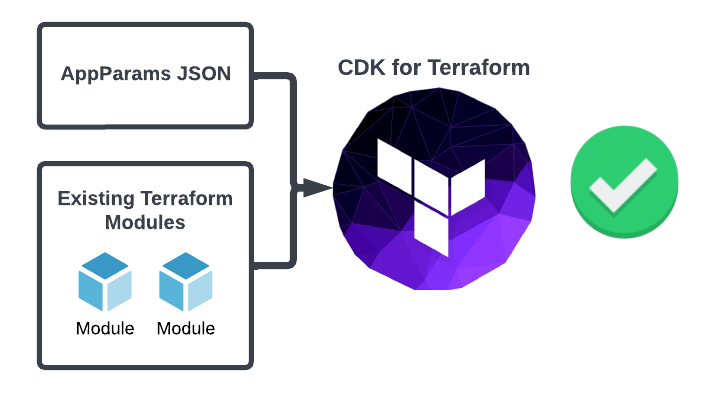
We would utilize our existing Terraform modules within the CDK scripts
We would encapsulate all variables for each application in a single, well-documented TypeScript type called AppParams.
An application's entire cloud stack would be generated by the CDK. This includes the CI/CD pipeline, DNS records, loadbalancing rules, ECS resources, permissions, and any pre-production/multi-region/cross-account replicas.
The CDK Way
Though the finer details of our implementation will appear in a future blog post, here is a cut-down example of our current implementation.
Using our "AppParams" TypeScript type, we define an application.
{
"name": "speedtest-api",
"git_branch": "main",
"tags": {
"app": "speedtest-api",
"product": "ookla",
},
"ecs_app": {
"create_iam_roles": true,
"max_capacity": 10,
"min_capacity": 3,
"desired_count": 3,
"cpu_target": 70
},
"deployment": {
"codepipeline_definition": {
"stages": [
{
"name": "Source",
"actions": [
{
"account_id": "1234567890",
"region": "aws-region-1",
"config": "SourceGithub"
}
]
},
{
"name": "Build",
"actions": [
{
"account_id": "1234567890",
"region": "aws-region-1",
"config": "Build"
}
]
},
{
"name": "Staging",
"actions": [
{
"account_id": "1234567890",
"region": "aws-region-1",
"config": "CodeDeployToECS"
},
{
"account_id": "1234567890",
"region": "aws-region-2",
"config": "CodeDeployToECS"
}
]
},
{
"name": "Production",
"actions": [
{
"account_id": "1234567890",
"region": "aws-region-1",
"config": "CodeDeployToECS"
},
{
"account_id": "1234567890",
"region": "aws-region-2",
"config": "CodeDeployToECS"
}
]
}
]
}
},
"loadbalancing": { ... }
}
This configuration will be used by the CDK script to create a CodePipeline that will build and deploy our application into two stages: Staging and Production, both into two AWS regions, and all within the same AWS account. Production will have CPU-utilization-based autoscaling enabled for up to 10 container instances.
The key to understanding this configuration is the codepipeline_definitions block, specifically the list of stage actions. Each action object represents a single CodePipeline Action. The nested config parameter can be one of two TypeScript types: a string, or an object representing a CodePipeline Action config. The CDK is configured to detect certain string values as "magic strings" that result in some helpful behavior. For example, in the above example, we use:
"name": "Staging",
"actions": [
{
"account_id": "1234567890",
"region": "aws-region-1",
"config": "CodeDeployToECS"
}
]
In this case, config is string CodeDeployToECS. CodeDeployToECS is one of these "magic strings," and will cause the CDK to generate Terraform to define the ECS service, IAM Task roles, Target Groups, CloudWatch alarms, and any other supporting infrastructure bits we need to successfully deploy the Staging stage of this application to AWS Account 1234567890 in the aws-region-1 region. The resulting CodeDeploy Action added to our CodePipeline will be configured accordingly.
Behind the scenes, the CDK script is leveraging all of our existing Terraform modules to define the infrastructure. However, we no longer have to copy and paste any HCL! The application is remarkably consistent region-to-region, stage-to-stage, and account-to-account, given that the CDK handled all duplication of resources and not a clumsy human. Any changes to the AppParams object propagate to all replicas and stages when the CDK synthesizes the Terraform code. Who needs humans, anyway?
To demonstrate the usage of our existing modules, here is an example of one of our custom Resources, which is used to create IAM roles. The key takeaway here is the call new IamApp -- this is the CDK utilizing our pre-existing "iam-app" module referenced earlier. This module defines Terraform resources for IAM Task Roles and some standard IAM permissions statements that our applications often need, such as access to S3 buckets for shipping logs and accessing centralized configurations for our service mesh.
export class OoklaIamRole extends Resource {
public readonly iamRole: IamApp;
constructor(scope: OoklaStack, name: string, props: OoklaIamRoleProps) {
super(scope, name);
const {
appName,
env,
accountId,
region,
identifiers,
policyArns,
} = props;
this.iamRole = new IamApp(scope, `IamApp-${appName}-${accountId}-${region}-${env}`, {
providers: [scope.awsProviders[accountId][region]],
name: appName,
env: env,
identifiers: identifiers,
policyArns: policyArns,
});
...
With our module now represented as a TypeScript class, we can do whatever we want with it; remove it conditionally, modify it, loop over it - anything we can express with TypeScript.
Looking Ahead
Eventually, our vision is that any product team at Ookla will be able to create and maintain these AppParams objects. The SRE team (or better yet, our automated tooling) will use these objects to quickly synthesize the Terraform needed to build, run, modify, and monitor the application. All of our rules and opinions on how we run an application within AWS will be codified (literally). In theory, this should also allow future SRE hires to better get up to speed on how the team manages new and existing applications.
In a future post, we will dive more into the structure of the CDK scripts themselves and discuss several interesting problems and solutions we've run into as we continuously iterate on our ideas and goals for this project.